이전 직장에서는 Java와 Spring을 사용했지만, SI 환경 특성상 트래픽이 많지 않아 트러블 슈팅을 경험할 기회가 적었습니다. 이후 Node.js 환경을 거치며 Java 힙 덤프를 직접 다룰 일은 더욱 없었습니다. "개발자는 언제든 장애 상황에 대비되어 있어야 한다"는 멘토님의 조언을 계기로 힙 덤프 분석을 개인적으로 학습해둔 것이, 이직 후 트러블 슈팅에 큰 도움이 되었습니다.
[문제 상황: 원인 모를 CPU 급증과 서버 다운]
새로 합류한 팀에서는 특정 시간대 트래픽이 몰리면 CPU 사용량이 급증하며 서버가 다운되는 고질적인 이슈가 있었습니다. 당시에는 원인을 정확히 파악하지 못한 채 서버를 스케일 업하거나 재부팅하는 임시 방편으로 대응하고 있었습니다.
가장 큰 문제는 OOME(Out Of Memory Error) 발생 시 자동으로 덤프를 생성하는 옵션(-XX:+HeapDumpOnOutOfMemoryError)이 설정되어 있지 않다는 점이었습니다. 입사 초기라 운영 환경의 배포 설정을 변경하고 재배포하는 것이 부담스러웠기에, 병목이 발생하는 시점에 맞춰 운영 EC2 서버에서 직접 명령어를 수행해 힙 덤프를 확보하기로 결정했습니다.
jmap -dump:format=b, file=dump.hprof [pid](물론, 정석은 OOME 발생 시 자동 덤프 옵션을 활성화하는 것입니다.) 확보한 덤프 파일을 Eclipse MAT으로 분석했습니다.
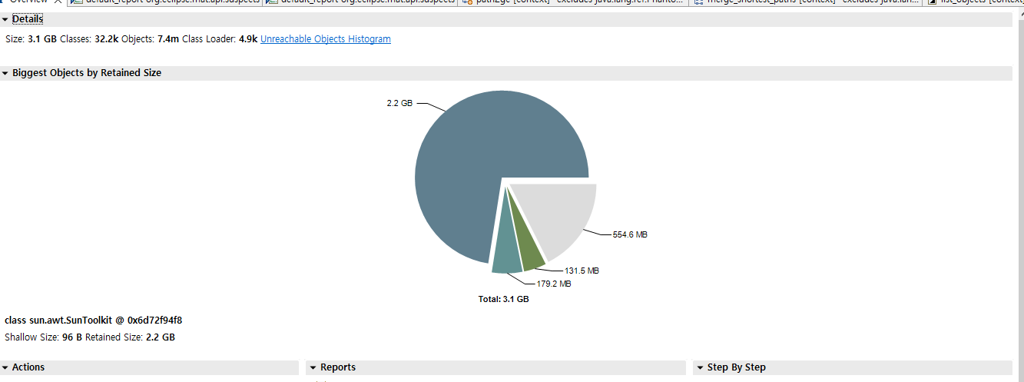
힙 메모리의 50% 이상을 특정 객체가 점유하고 있었습니다.

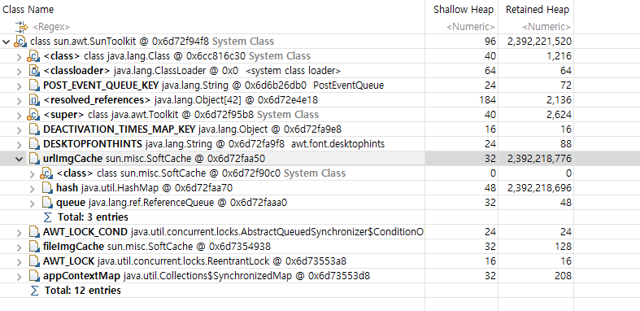
char[] 배열이 메모리를 과도하게 차지하고 있었으며, 이를 추적해보니 AWT 관련 라이브러리와 연관된 것을 확인했습니다.
코드를 역추적한 결과, 화면 뷰(View) 로직에 문제가 있었습니다. 서버에서 이미지를 보여줄 때, 이미지를 Base64로 변환하여 전송하고 뷰에서 다시 이미지화하는 레거시 로직이 원인이었습니다. 접속자가 몰리면서 Base64 변환 작업이 폭증했고, 이로 인해 버퍼가 쌓이며 **CPU 부하(변환 연산)와 OOME(메모리 누적)**가 동시에 발생했던 것입니다.
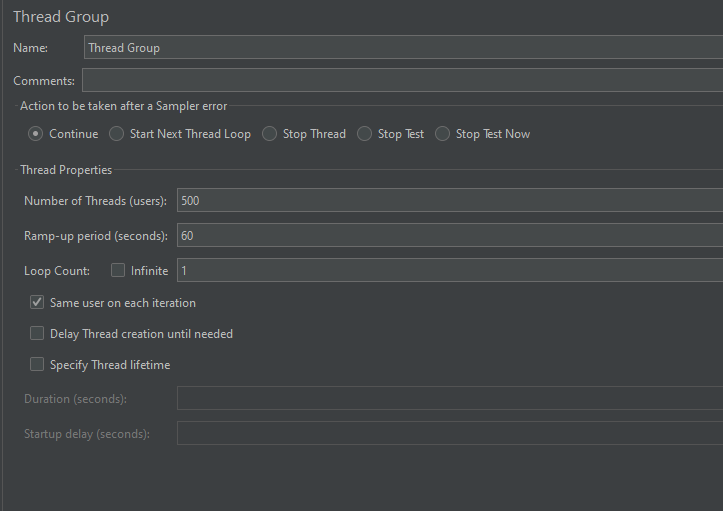

가설을 검증하기 위해 JMeter를 사용하여 부하 테스트를 진행했습니다. 운영 서버와 유사한 환경을 구성하고 충분한 웜업(Warm-up) 과정을 거친 뒤 테스트를 수행했습니다.
그 결과, 운영 서버 장애 시점과 매우 유사한 메모리 그래프를 그리며 OOME가 재현되었습니다. 원인이 명확해진 덕분에 해당 로직을 개선할 수 있었고, 이후 서버는 안정화되었습니다.

위 내용은 보고서로 작성하여 내부에 공유하였습니다. 당시에는 조금 당황했지만 그래도 트러블슈팅을 만나는 건 굉장히 중요한 경험인 것 같습니다.
'BackEnd > JAVA' 카테고리의 다른 글
| RSA를 이용한 민감정보 암호화 적용 (0) | 2025.12.15 |
|---|---|
| LocalDateTime 타임존에 대한 이해 (0) | 2024.11.05 |
| [자바 JVM 모니터링]VisualVM을 통한 모니터링 해보기 (0) | 2024.10.30 |
| [용어정리] JCP, JSR, JSR-310 정리 (0) | 2024.10.16 |
| 실수형 표현이 정확하지 않은 이유? (0) | 2024.10.05 |

