데이터베이스에서 운영 시 가장 중요한 두 가지는 확장성과 가용성이다 대용량 트래픽을 처리하기 위해서 데이터베이스를 확장될 준비가 되어있어야하며, 문제가 발생했을 때 언제든지 복원되고 유지되어야한다. Replication을 통해서 얻을 수 있는 이점은 성능상의 이점과 고가용성에 있다고 생각한다
- 확장성
- RDBMS는 스케일 아웃이 힘들다 NoSQL 대비해서 데이터 정합성을 우선시 하기 때문이다
- 현대 온라인 서비스에서 쓰기와 읽기 비율은 비교했을 때 8:2 정도의 비율을 가진다
- Replication을 통해서 쓰기와 읽기를 분리하여 성능상의 이점을 가져올 수 있다
- 가용성
- 만약 원본 DB가 장애가 나서 복원을 해야한다고 가정하자 백업 간격이 길수록 데이터 손실이 발생한다
- 물리적인 손상이 발생했을 때 서비스 복원과 더불어 데이터 손실을 최소화해야한다
- Replication을 통해서 실시간 백업과 동시에 장애를 감지하고 복원을 할 수 있다
복제 타입
설정 방법에는 바이너리 로그 파일 위치 기반과 GTID 기반이 있다.
바이너리 로그 파일
- MySQL에 복제 기능이 처음 도입되었을 때 제공된 방식이다
- 바이너리 로그 파일과 위치(Offset)을 통해서 식별한다
- MySQL 5.5까지는 바이너리 로그 파일 위치 기반만 제공했다
하지만 바이너리 로그파일 위치 기반에는 단점이 있다
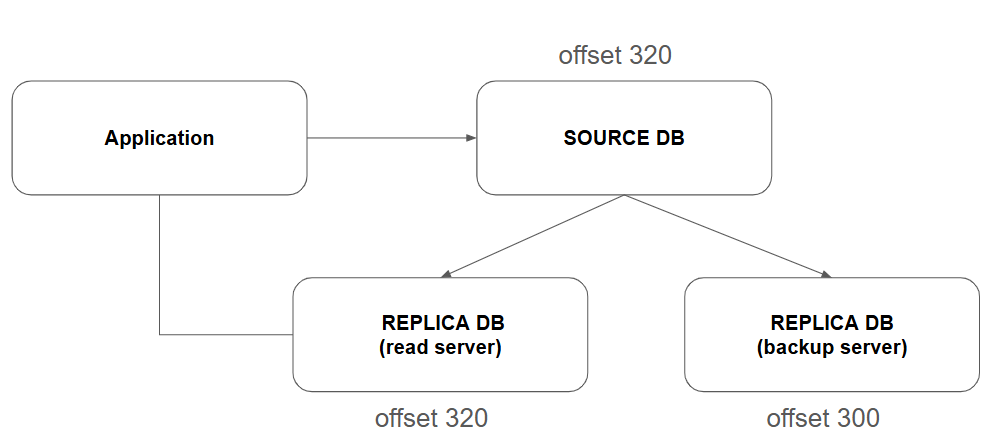
위와 같이 구성되어있다고 가정하자 허나 백업서버의 경우 성능상의 이슈로 지연복제를 하고 있는 과정에 있어 아직 소스 DB의 오프셋을 전체 복제하지 못했을 때 장애가 발생했다면 어떤 문제가 발생할까?

위와 같이 소스 DB의 문제로 레플리카 DB가 소스 DB로 승격하고 백업 DB를 연결해야한다 헌데 파일기반 복제는 마스터의 파일 위치만 알 수 있다. 만약 문제가 발생되면 동기화되지 못한 데이터는 복구하기 힘들다. 소스서버가 바뀌면 바이너리 파일 자체가 변경되는데 복제서버이지만 파일 offset은 동일하다고 볼 수 없다
Replication DB의 바이너리 로그는 릴레이 로그 기반으로 작성되고 복제된 시점이 제각기이기 때문에 바이너리 로그가 마스터와 동일한 개념이라고 보면 안된다. 결론적으로 데이터 손실의 문제가 발생한다. 그렇기 때문에 GTID 기반을 다수가 선호한다
GTID (Global Transaction ID)
- 서버에서 커밋된 트랜잭션과 연결된 고유 식별자이다
- 바이너리 로그에 기록된 트랜잭션에 한해서 할당된다
- GTID = [source_id]:[transaction_id] 기반으로 표기되며 모든 레플리카 DB에 적용되기 때문에 이전 문제에 대해서 해결될 수 있다
GTID 기반 Replicaiton 설정하기
1. MySQL 서버 준비
Virtual Machine으로 Centos를 설치 후 MySQL를 설치한 상태이다. (2개의 가상머신이 필요하며 같은 네트워크에 있어야한다)
MySQL은 8.4 버전기준으로 진행했다.
2. Source DB 설정하기

기본적으로 MySQL에 설정파일은 mysql —help라고 치면 위와 같이 순차적으로 나온다
/etc/my.cnf파일을 vi로 실행하면 아래와 같이 표기된다

설정 파일은 dir에 있는 파일을 include하는 방식이다 /etc/my.cnf.d로 가면 mysql-server.cnf를 수정할 수 있다

위 내용을 작성 시 Replication 설정에 필수적인 것만 말해보자면 다음과 같다
[mysqld]
server_id=1
gtid_mode=ON
enforce_gtid_consistency=ON
log_bin=mysql-master-bin
위 설정 필수적이며 server_id는 무조건 1일 필요는 없지만 다른 replication DB와 겹치면 안된다
그리고 Root 계정으로 접속해서 다음과 같이 Replication 계정을 만들어준다
CREATE USER replica@'%' IDENTIFIED WITH 'caching_sha2_password' BY 'password';
GRANT REPLICATION SLAVE ON *.* TO replica@'%';
FLUSH PRIVILEGES;
그 이후 마스터 dump를 수행한다
mysqldump -u root -p \
--opt \
--all-databases \
--single-transaction \
--set-gtid-purged=ON \
--master-data=2 > /tmp/master_dump.sqldump 시 현재 운영중인 서버로 진행했을 때 문제가 없는지 반드시 확인해야한다
3. replica DB 세팅하기
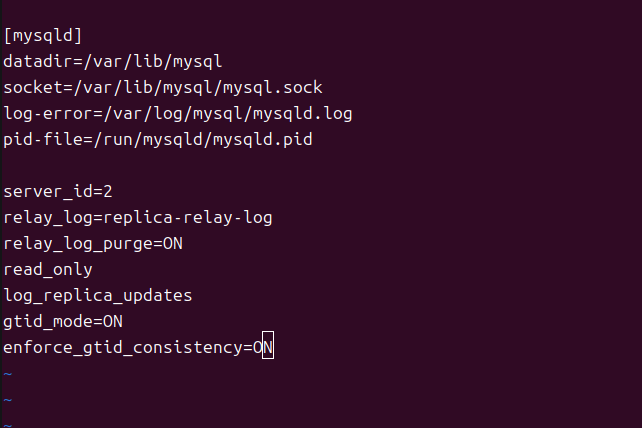
설정해야하는 설정이며 replication을 위한 설정은 다음과 같다
server_id=2
relay_log=replica-relay-log
relay_log_purge=ON
read_only
log_replica_updates
gtid_mode=ON
enforce_gtid_consistency=ON
Server id는 Source DB, 다른 Replication DB와 겹치지 않아야한다
import Dump
mysql -u root -p < master_dump.sql
아까 dump 뜬 파일을 replica DB에서 import 수행해준다
CHANGE REPLICATION SOURCE TO
SOURCE_HOST='192.168.0.52',
SOURCE_PORT=3306,
SOURCE_USER='replica',
SOURCE_PASSWORD='password',
SOURCE_AUTO_POSITION=1,
GET_SOURCE_PUBLIC_KEY=1;
START REPLICA;
import과 완료되면 밑의 명령어를 수행해준다
4. 확인
정상적으로 수행중인지 확인해보려면 SHOW REPLICA STATUS 를 실행해본다
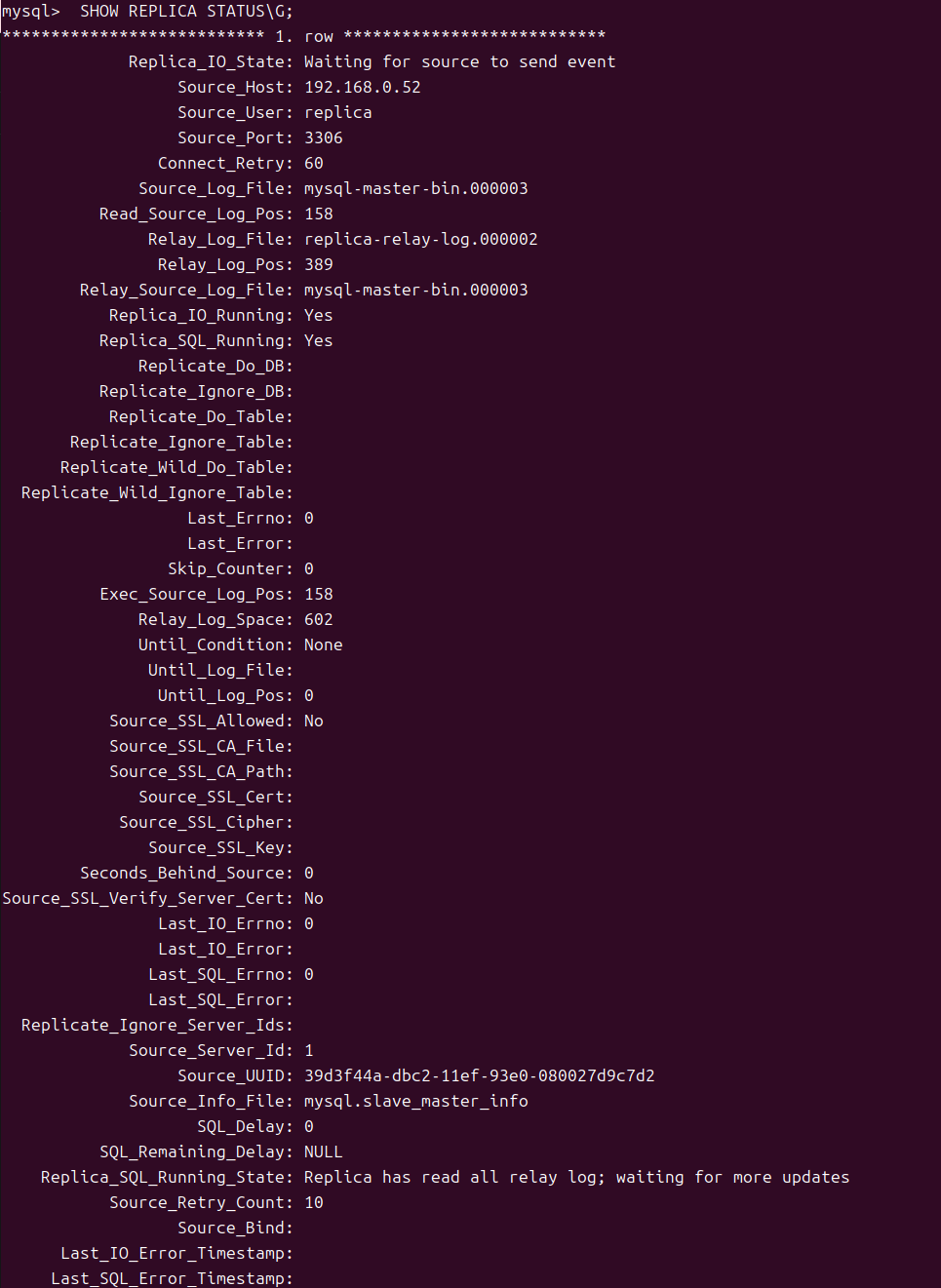
상태를 확인 후 에러가 없다면 SOURCE DB에서 수행된 쿼리가 정상적으로 Replication DB에 적용되는 지 확인해본다
'BackEnd > DB' 카테고리의 다른 글
| [쿼리 튜닝] 슬로우 쿼리 문제 해결하기/쿼리 성능 개선 (0) | 2025.02.04 |
|---|
